
The second edition of the Dataninja Spring-School was held from 8th to 10th of May 2023 in Bielefeld and as a hybrid event. We had the honor and pleasure to attend talks and tutorials from renowned researchers and aspiring young scientists.
We contributed with an extended abstract and our scientific poster “Finding the Relevant Samples for Decision Trees in Reinforcement Learning” presented during Tuesday’s poster session. The opportunity for fruitful discussions and interactions with fellow PhD students from the Dataninja project was much appreciated!
The operation of nuclear power plants (NPPs) is one of the most safety-critical tasks in industry. Pri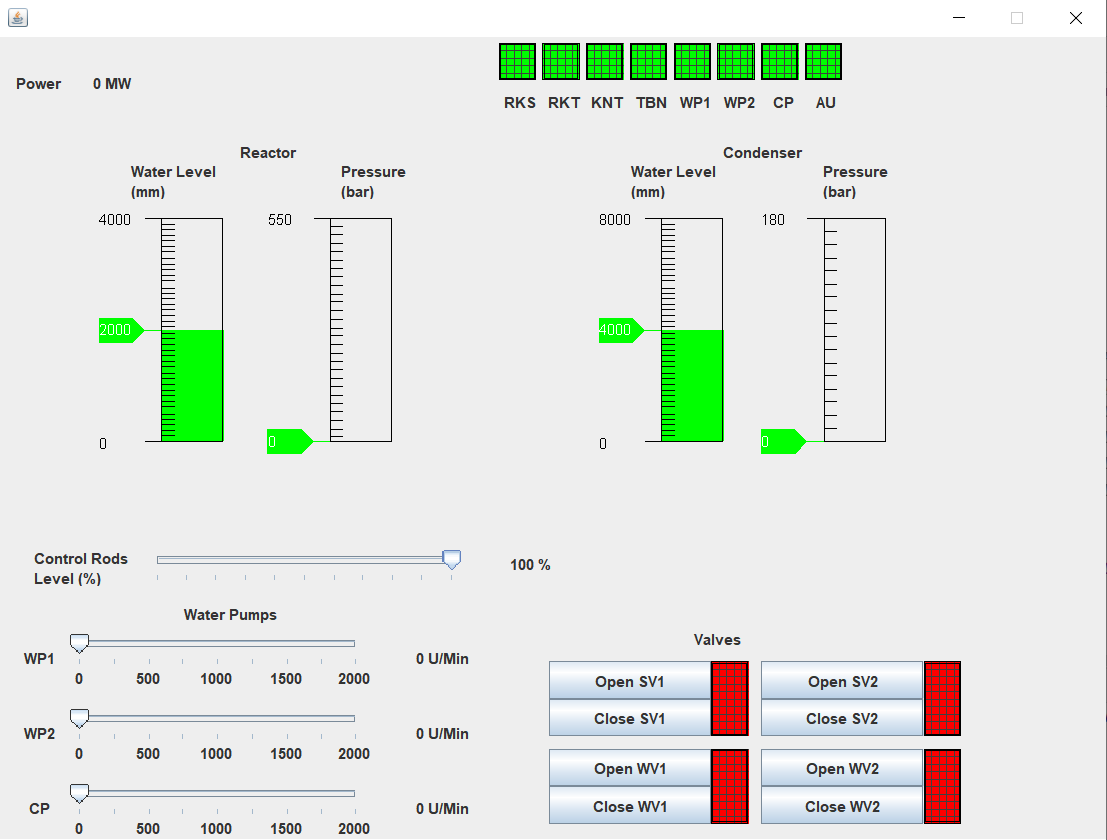 or to using AI methods in this area, it should be thoroughly investigated and evaluated via simulations, whether AI can learn (e.g.´, by reinforcment learning, RL) to power up and shut down a nuclear reactor and how well such an approach meets the safety requirements. This was exactly the task of Niklas Fabig's master thesis which he conducted under the supervision of Prof. Dr. Wolfgang Konen and PhD-candidate Raphael Engelhardt as part of our (RL)^3-project as part of https://dataninja.nrw/. The works uses as a starting point a Java-based NPP simulation tool from Prof. Dr. Benjamin Weyers, University Trier (screenshot example in image). Niklas Fabig constructed first a Java-Python bridge and then conducted over 2000 RL simulation experiments under various settings. He could show that RL algorithms can learn the power-up procedure yielding high returns, but much more research is needed to reliably meet the safety requirements.
or to using AI methods in this area, it should be thoroughly investigated and evaluated via simulations, whether AI can learn (e.g.´, by reinforcment learning, RL) to power up and shut down a nuclear reactor and how well such an approach meets the safety requirements. This was exactly the task of Niklas Fabig's master thesis which he conducted under the supervision of Prof. Dr. Wolfgang Konen and PhD-candidate Raphael Engelhardt as part of our (RL)^3-project as part of https://dataninja.nrw/. The works uses as a starting point a Java-based NPP simulation tool from Prof. Dr. Benjamin Weyers, University Trier (screenshot example in image). Niklas Fabig constructed first a Java-Python bridge and then conducted over 2000 RL simulation experiments under various settings. He could show that RL algorithms can learn the power-up procedure yielding high returns, but much more research is needed to reliably meet the safety requirements.
The investigation carried out by Niklas Fabig constitutes very interesting and brand-new research in this field, which has now led to winning the 3rd place in the Steinmüller Engineering Award 2023. His supervisor Wolfgang Konen was deeply impressed by the solid, comprehensive and innovative work done by Niklas Fabig and congratulates him warmly. It should be noted, that the master thesis was conducted in the Corona years 2021 - 2022 and so the supervision had to be fully online. Nevertheless, the result of the work and the motivation of Niklas Fabig was by no means less than if the supervision had taken place in presence.

View from Certosa di Pontignano
As previously announced, last week I had the pleasure to present our joint work with our partners from Ruhr-University Bochum on explainable reinforcement learning at the 8th Annual Conference on machine Learning, Optimization and Data science (LOD). The presentation sparked interesting questions and lead to inspiring discussions in the enchanting ambiance of the medieval monastery in Tuscany.
As the conference was held in conjunction with the Advanced Course & Symposium on Artificial Intelligence & Neuroscience (ACAIN), we could profit from a very stimulating interdisciplinary environment with talks, tutorials, and posters covering topics reaching from the biology of neuronal development to implementation details of different deep learning frameworks.
We are looking forward to LOD 2023!
The second edition of the annual Dataninja-Retreat took place this September in Tecklenburg. The different Dataninja projects presented their proceedings, we had the pleasure of attending a lecture by Prof. Xiaoyi Jiang, and fresh PhD graduates of the KI-Starter-project kindly shared experiences and some tips from their recently concluded PhD-journey. Last but not least it was of course a very pleasant and rare occasion for seeing each other offline, exchanging ideas, experiences, struggles, and successes.

Group picture of the participants
We are pleased to announce that we will present our research on explainable reinforcement learning at the 8th Annual Conference on machine Learning, Optimization and Data science (LOD).

Carthusian monastery in Pontignano Siena, Italy. Venue of LOD 2022
Starting with its first edition in 2015, the LOD is an established international and interdisciplinary forum for research and discussion of Deep Learning, Optimization, Big Data, and Artificial Intelligence. This year's 8th edition of the will be held online and onsite in Pontignano near Siena, Italy on September 18th - 22nd 2022.
Reading the conference's manifesto “The problem of understanding intelligence is said to be the greatest problem in science today and ‘the’ problem for this century” we find this prestigious conference to be the perfect place to present our work targeted at making deep reinforcement agents explainable.
We are very grateful for the opportunity to present our paper titled “Sample-based Rule Extraction for Explainable Reinforcement Learning”, which outlines the results of our ongoing research of inducing simple, transparent, human-readable rules from well-trained deep reinforcement learning agents. A link to the article will be added as soon as it is published. For those interested, early registration for the conference is available until Sunday July 31st, 2022.
 In September 2021, shortly after the Dataninja retreat, we participated at the KI 2021 – 44th German Conference on Artificial Intelligence.
In September 2021, shortly after the Dataninja retreat, we participated at the KI 2021 – 44th German Conference on Artificial Intelligence.
Alongside fellow members of the Dataninja research training group we, Raphael Engelhardt and Wolfgang Konen from TH Köln together with Laurenz Wiskott and Moritz Lange from RUB Bochum, presented our work on rule extraction from trained reinforcement learning agents in a poster session as part of the workshop "Trustworthy AI in the wild". The conference had to be held virtually which did not affect some very interesting discussions and exchange of new ideas.
Our poster as well as the extended abstract are available online.

Between the third and fourth wave of the COVID-19 pandemic, we were in September 2021 lucky enough to hold in presence the annual retreat of the Dataninja research group, which was at the same time the group's first ever in-person meeting. The rich and balanced program included presentations of the different Dataninja projects by the respective PhD candidates, scientific talks by guest speakers, networking and outdoor activities in the nature surrounding Willingen.
While the science was top notch, there is definitely room for improvement regarding steering a canoe as the following tracking picture of one of the canoes shows 🙂 ...
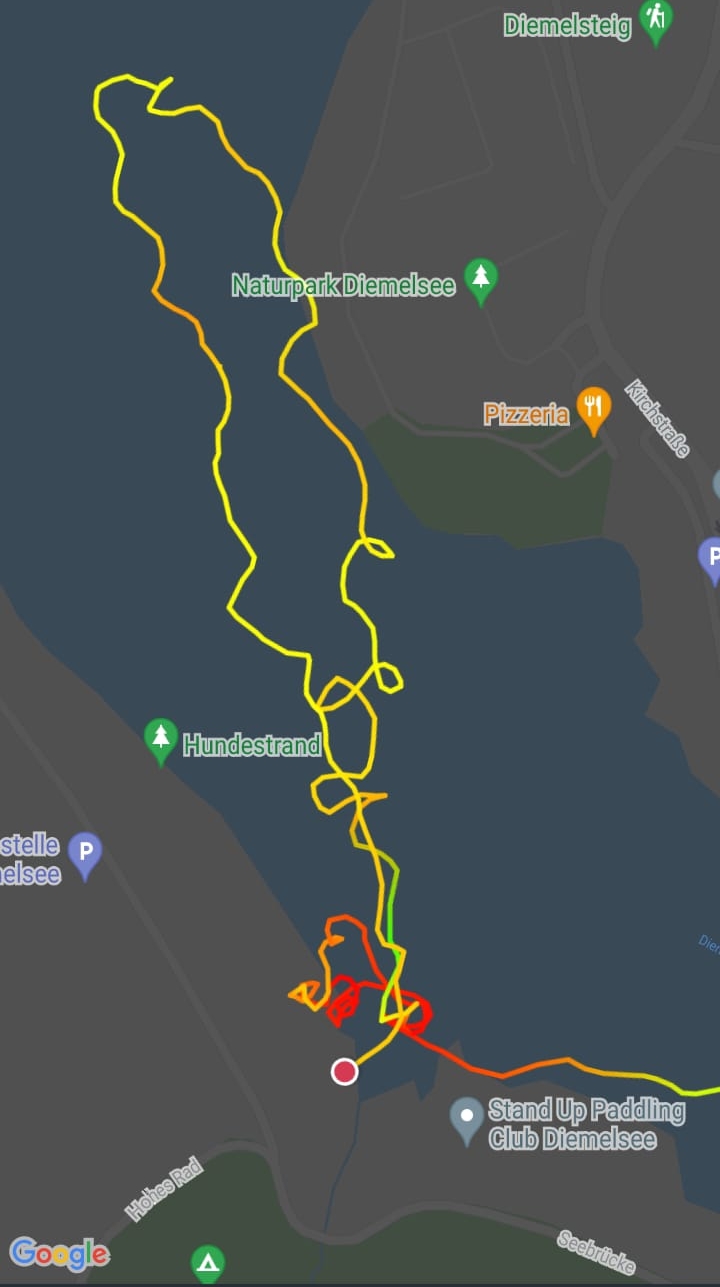
(Image: Christoph J Kellner)
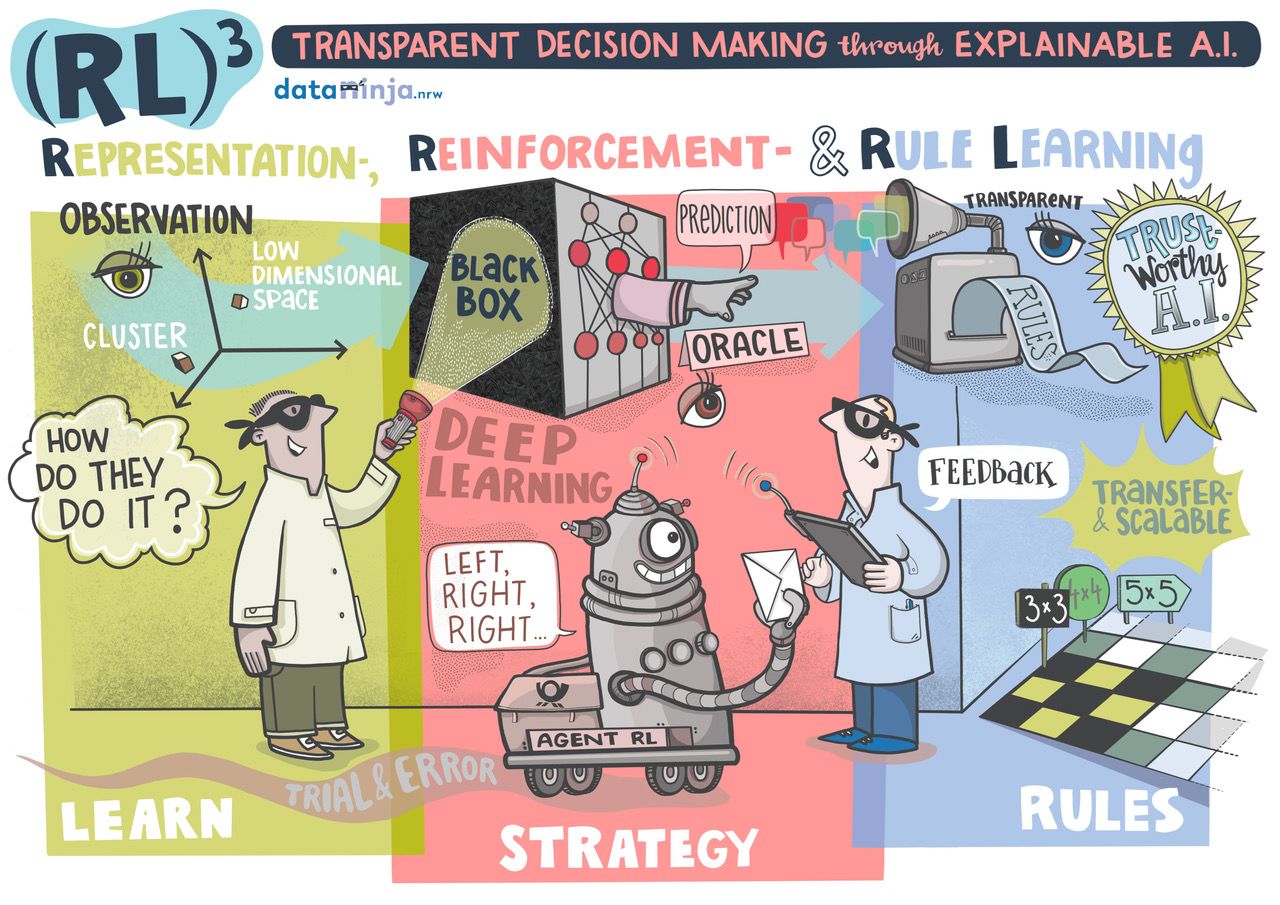
For the research project (RL)^3, which is lead by Laurenz Wiskott (RUB) and Wolfgang Konen (TH Köln) and that is illustrated in the figure above, there is now a press release TH Köln available: https://www.th-koeln.de/hochschule/mehr-transparenz-bei-kuenstlicher-intelligenz_84905.php (sorry, in German only!).
(RL)^3 is part of the graduate school Dataninja (Trustworthy AI for Seamless Problem Solving: Next Generation Intelligence Joins Robust Data Analysis).

We are happy to announce the dataninja.nrw inauguration event that takes place virtually on Monday, May, 3rd, 16-18.
Our research group (RL)^3 at TH Köln is part of the AI graduate school dataninja.nrw with a PhD tandem together with Ruhr University Bochum.
Please see the attached PDF dataninja_inauguration_05_03 for all the details and the programme of the inauguration event and how to register.
All interested people are free to join this event!
(RL)^3 is part of the graduate school dataninja.nrw (Trustworthy AI for Seamless Problem Solving: Next Generation Intelligence Joins Robust Data Analysis).
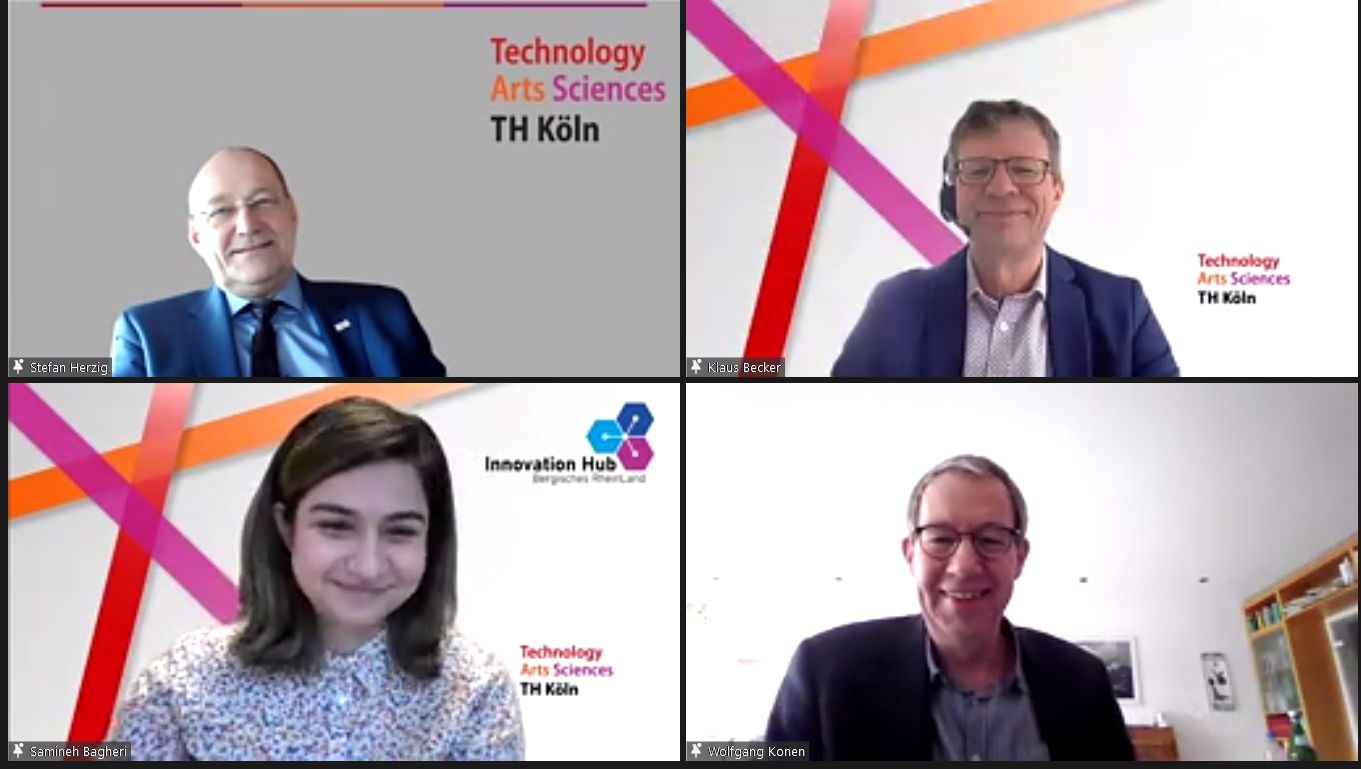 We are happy to announce that Samineh Bagheri won the Dissertation Price 2020 of TH Köln for her PhD thesis. Her thesis “Self-Adjusting Surrogate-Assisted Optimization Techniques for Expensive Constrained Black Box Problems” deals with state-of-the art optimization algorithms supported by RBF surrogate models.
We are happy to announce that Samineh Bagheri won the Dissertation Price 2020 of TH Köln for her PhD thesis. Her thesis “Self-Adjusting Surrogate-Assisted Optimization Techniques for Expensive Constrained Black Box Problems” deals with state-of-the art optimization algorithms supported by RBF surrogate models.
The award ceremony took place online - as usual in these times - on Monday, Feb, 22nd, 2021, and was conducted by vice president Prof. Klaus Becker (upper row, right), attended by all other members of the presidential committee, including president Prof. Stefan Herzig (upper row, left) and of course the laureate Dr. Samineh Bagheri (lower row, left) and her supervisor Prof. Wolfgang Konen (lower row, right).
Read more about the dissertation price and Samineh Bagheri in this THK-News (sorry, in German only!)
Read more about Samineh's PhD-colloquium (the first fully-online colloq at Leiden University) in this CIOP blog post.